A popular school of thought in LLM evaluation starts with production traces. Collect outputs, have a domain expert annotate them, and gradually build your evaluation criteria from observed failures. The approach is grounded and empirical. In our experience, it also suffers from a core problem: it over-complicates evaluation to the point where expert availability becomes the bottleneck, treating LLM development more like a sociological study than a software engineering discipline.
We have seen teams spend weeks annotating traces before writing a single eval. The predicate-first approach starts from a different premise entirely. For well-defined automations, starting with traces is an expensive, backward inversion of standard engineering practice. You already know what "correct" looks like. Write it down as a formal predicate, and let a judge verify it from Day 0.
1. The Epistemological Error: Inverting the Contract
Standard engineering defines a contract first, then verifies against it. Trace-first evaluation reverses this: it observes outputs and inductively guesses what the contract should have been.
The problem is that projects are rarely built "blindly." Latent specifications already exist before the first prompt is written. PRDs describe expected behavior. SLAs define acceptable latency and uptime. JSON schemas constrain output structure. KPIs quantify business success.
By deferring to production traces, the trace-first framework normalizes the absence of upfront specification as a permanent state. Predicate-first evaluation formalizes this latent intent into executable judges on Day 0. The specification was always there. It just needs to be made explicit and testable.
2. The Efficiency Gap: Architecting a Permanent Bottleneck
Trace-first methodologies typically require a domain expert to manually annotate dozens or hundreds of traces before any automated evaluation can begin. The reasoning is sound: you need "theoretical saturation" to understand the failure space. In practice, this creates a permanent human bottleneck.
Expert time is the most expensive resource on any AI team. Every hour spent manually labeling traces is an hour taken away from system design, prompt engineering, or shipping features. The predicate-first approach dramatically reduces the "time to first eval" by using synthetic cross-model data.
Here is what that looks like in practice: use a different model family (for example, Claude to generate test inputs for a GPT-based system) to produce edge-case inputs. This breaks same-model bias and enables genuine Test-Driven Development for LLM applications. The judge is calibrated against the specification, not against a sample of past failures.
Consider a customer support bot. Predicates for this system might include: "response must cite a knowledge-base article ID," "refund offers must not exceed the customer's order value," and "tone must match brand voice guidelines." Every one of these is testable on Day 0, with synthetic inputs, before a single real user interaction. Building custom evaluators from policies is exactly what this LLM evaluation framework enables.
Predicate-first evaluation formalizes existing specifications into executable judges before production deployment.
3. Strategic Risk: Reactive vs. Contractual Governance
The failure-mode taxonomy that trace-first evaluation produces is inherently backward-looking. If a failure has not yet appeared in your sampled traces, it does not exist in your evals.
For regulated or high-stakes domains (healthcare, fintech, legal), this is untenable. You cannot certify a system based on a catalog of past mistakes. Certification requires verification against affirmative properties: predicates that define what the system must do, independent of what it has done so far.
Trace-first methodology de-prioritizes proactive red-teaming. A predicate-first approach defines "safe" and "correct" boundaries upfront, ensuring the system is judged against the entire risk surface. The eval suite covers the "known knowns" before any user sees the product, rather than waiting for production failures to reveal gaps.
4. Technical Fragility: Binary Over-Simplification
Trace-first practitioners often advocate for binary pass/fail scoring to simplify the human labeling process. For quick quality checks, this works fine. For complex optimization, it destroys the variance information that teams actually need.
Business KPIs are rarely binary. They involve trade-offs: accuracy vs. tone vs. latency vs. cost. A single expert annotator encodes a single stakeholder's perspective. Predicate-first evaluation allows for multi-objective scoring, where different stakeholders (Legal, Product, Brand) define independent predicates. A judge can aggregate these into a quality signal that actually reflects how the business measures success. The difference between LLM-as-judge and human evaluation is that automated judges scale this process across every deployment.
The Methodological Divide
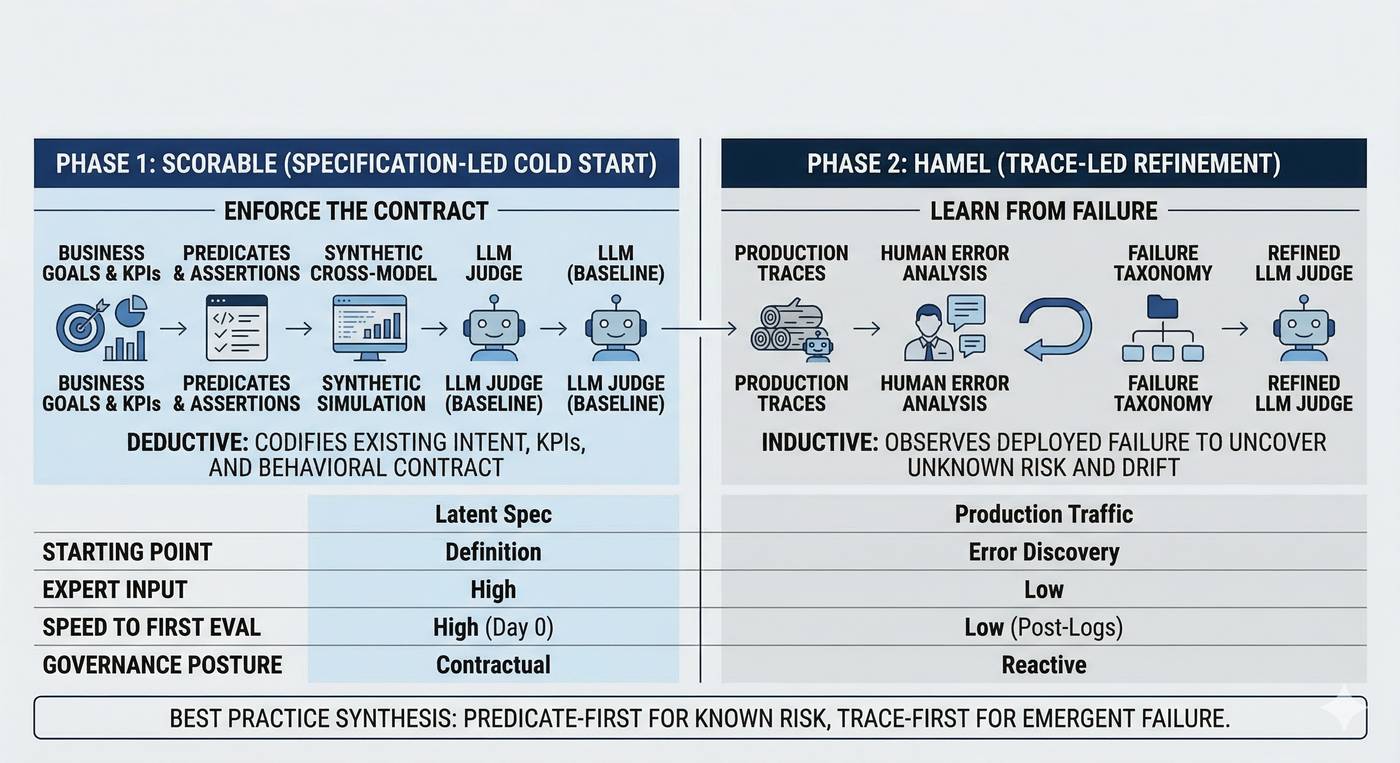
| Feature | Trace-First (Inductive) | Predicate-First (Deductive) | | ---------------------- | -------------------------------------------- | ----------------------------------------------- | | Core logic | "Observe failures to find rules." | "Define rules to find failures." | | Philosophy | Grounded Theory (Social Science) | Formal Specification (Systems Engineering) | | First action | Review hundreds of production traces | Formalize KPIs into predicates | | Data strategy | Real-world traces (high fidelity, low speed) | Synthetic + spec-driven (high speed, proactive) | | Governance posture | "We fixed what we saw." | "We verified what we promised." |
The Synthesis: Spec-First for Knowns, Trace-First for Unknowns
These two approaches are complementary, and the practical conclusion is straightforward: trace-first evaluation works best as a refinement layer stacked on top of a predicate-first foundation.
Phase 1 (Predicate-First): Define the value and risk structure using existing KPIs. Build a "v0" judge using synthetic inputs and structural predicates. This provides a governance layer that catches the known-knowns before any user interacts with the product.
Phase 2 (Trace-Informed): Once in production, use trace analysis to discover the unknown-unknowns: the emergent failures that no specification could predict. Feed these discoveries back into the predicates to update the behavioral contract over time.
The deepest gap in the trace-first worldview is the conflation of "expert-led" with "manual." Evaluation should be an automated extension of the product requirements, built into the development lifecycle from the start.
Get Started with Predicate-First Evaluation
Scorable makes predicate-first LLM evaluation best practices accessible to any team. Define your first predicate in under five minutes, generate synthetic test data from your existing specifications, and ship with confidence that your system does what you promised it would do. Start your free trial and build your AI evaluation framework today.